IndexFiguresTables |
Seok-Hun Choi , Mugeun Baek and Seok-Jun BuuDiffusion Model-based In-vehicle Noise Augmentation through Expert Knowledge-guided ClusteringAbstract: To ensure vehicle operational safety and enhance user experience, it is crucial to accurately classify in-vehicle noise and detect performance anomalies in advance. However, deep learning-based noise classifiers often struggle in complex acoustic environments, such as those with external noise and internal reverberation. To address these challenges, we propose a novel vehicle noise classification method that integrates diffusion model-based signal augmentation with expert knowledge-guided clustering. This approach synthesizes a variety of challenging in-vehicle acoustic conditions and enhances signal-label associations through automatic label assignment based on expert-defined clusters. As a result, we can create training datasets that closely mirror real-world scenarios. Our experiments demonstrate that this method achieves a classification accuracy of 99.60%, surpassing state-of-the-art classifiers and improving by 0.06 percentage points over existing generative augmentation methods, thereby showcasing the effectiveness of the diffusion-based approach. Keywords: diffusion models , generative deep learning , data augmentation , acoustic classification , in-vehicle noise classification 최석훈, 백무근, 부석준전문가 지식을 활용한 군집화를 통한 확산 모델 기반 차량 내 소음 증강요 약: 차량 운행의 안전성과 사용자 경험 향상을 위해, 차량 내 소음을 정확히 분류하고 이를 기반으로 성능 이상을 사전에 예측하는 기술이 중요하다. 그러나 기존 딥러닝 기반 분류기는 외부 잡음, 내부 반향음 등 복잡한 음향 환경에서 성능 저하를 보인다. 본 논문에서는 이러한 문제를 해결하기 위해, 확산 모델 기반 신호 증강으로 복잡한 차량 내 음향 환경을 모사하고, 신호–라벨 간 상관관계를 강화하는 데이터 증강 기법과 전문가 지식 기반 군집화 기법을 결합한 새로운 차량 소음 분류 기법을 제안한다. 제안한 방법은 다양한 소음 조건을 반영한 합성 데이터를 생성하고, 전문가 정의에 따른 군집화 기반 라벨링을 통해 실제 환경을 반영한 학습 데이터를 구성함으로써 분류 성능을 향상시킨다. 실험 결과, 본 방법은 최신 딥러닝 기반 분류기 대비 99.60%의 정확도를 달성했으며, 기존 생성 모델 기반 증강보다 0.06%p 높은 성능을 보여 그 효용성을 입증하였다. 키워드: 확산 모델, 생성적 딥러닝, 데이터 증강, 음향 분류, 차량 소음 분류 1. 서 론차량 내 소음의 정확한 분류는 차량의 성능을 진단하고 결함을 파악해서 안전성을 향상하는 중요한 일이다. 그리고 이는 사용자 경험 개선에 핵심적인 역할을 한다 [1]. 차량에서 발생하는 다양한 소음은 단순한 기계적 작동의 결과일 뿐만 아니라, 도로 상태, 운전 습관, 주변 환경 조건 등 외부 요인들에 의해 크게 영향을 받는다. 이러한 복잡한 요인들이 결합하여 차량 내부에서 다양한 음향 특성이 발생하며, 이는 시간에 따라 변동하거나 불규칙하게 나타나기 때문에 이를 효과적으로 분류하는 것은 매우 어려운 과제이다[2,3]. 기존의 분류 방법들은 이러한 배경 소음의 다양성과 차량 내부의 반향, 굴절 등으로 인해 소음의 복잡한 특성을 모두 반영하지 못해 제한된 성능을 보인다[3]. 복잡한 차량 내부 환경에서의 소음 분류를 위해서는 다변량 소음의 패턴 추출과 데이터의 다양성을 극대화하는 한 단계 높은 단계의 신호 증강 방법이 필요하다. 본 논문에서는 기존 소음 분류 기법들이 복잡한 차량 내 음향 환경을 충분히 반영하지 못해 성능에 한계를 보이는 문제를 해결하기 위해, 효과적인 데이터 증강과 분류 성능 향상을 목표로 한 새로운 접근법을 제안한다. 제안하는 방법의 주요 공헌은 확산 모델 기반 신호 증강과 전문가 지식 기반 군집화 기법을 결합하여 복잡한 소음 패턴을 보다 정확하게 반영할 수 있다는 점이다. 이 방법에서는 차량 내 소음 데이터가 확산 모델 기반 신호 증강 기법을 통해 생성한다. 그리고 생성된 데이터에 대해 전문가 지식 기반 군집화 과정을 거쳐 복잡한 데이터를 군집화 한다. 이렇게 증강된 데이터를 확보하여 분류기의 성능을 극대화한다. 이로써, 기존의 단순한 증강 방법들보다 더 복잡하고 다양한 소음 조건을 반영하면서도 고품질의 합성 소음 샘플을 생성할 수 있다. 본 논문에서 제시한 확산 모델 기반 신호 증강 방법은 전통적인 증강 방법과 딥러닝을 활용한 다른 증강 방법들에 비해 최소 0.06%p의 성능 향상이 있었으며, 이는 제안하는 방법이 더 복잡하고 다양한 소음 패턴을 학습하는 데 효과적임을 시사한다. 2. 관련연구표 1에서는 음향 데이터셋의 분류 정확도를 개선하기 위해 전통적인 증강 방법과 딥러닝 기반의 새로운 증강 방법을 적용하는 시도를 정리하였다. Flip, Rotate, Blur, Shift 등의 전통적인 증강 방법은 주로 간단한 기하학적 변형을 통해 데이터의 다양성을 높이는 데 초점을 맞추고 있다. 이러한 방법들은 특히 데이터셋의 크기가 상대적으로 작거나 특정 패턴에 과적합되는 것을 방지하는데 유용하다[4]. 예를 들어, Stanford Cars-196 데이터셋에서 이러한 전통적인 증강 방법들을 적용했을 때, 분류 정확도가 94.60%로 향상되었으며, 이는 이들 방법이 데이터의 여러 특성을 모델이 학습할 수 있도록 도와준 결과라 할 수 있다[4,5]. 표(Table) 1. 음향 데이터 및 증강 방법에 따른 분류 연구 (Related Work Utilizing URL and HTML for Phishing Detection)
그림(Fig.) 1. 차량 내 소음 분류를 위한 전체 구조 (Autoencoder-based Anomaly Detection and Multimodal Ensemble Method) 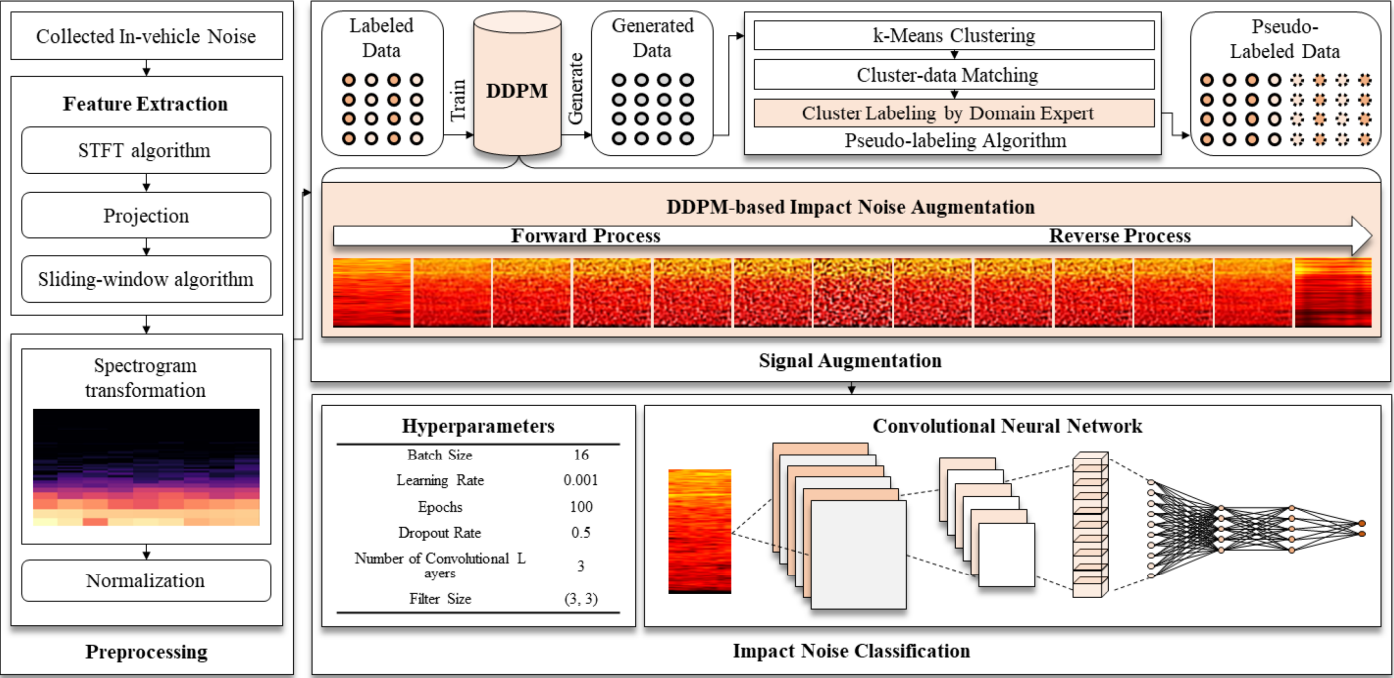 딥러닝 기반의 새로운 증강 방법들은 전통적인 방법들에 비해 더 복잡한 데이터 변형을 수행한다. GAN, ACGAN, DCGAN 및 DEVAE-GAN과 같은 생성적 적대 신경망(GAN) 기반 방법들은 실제 데이터와 유사한 새로운 데이터를 생성하여 모델의 학습에 사용된다. 이러한 방법들은 기하학적 변형을 통한 전통적인 증강기법보다 복잡한 신호 패턴을 포함하는 데이터셋에서 유용하며, 다양한 합성 데이터의 생성을 통해 모델이 다양한 상황을 학습할 수 있도록 한다. 이를 통해 UrbanSound8K, In-vehicle noise, EEG-based SEED 등의 다양한 데이터셋에서 각각 97.03%, 95.81%, 97.21%의 높은 분류 정확도를 기록하였다 [6-9 ] 기존의 데이터 증강 기법들은 차량 내 환경처럼 다양한 소음원이 혼재된 복잡하고 변칙적인 음향 조건에서는 효과가 제한적이다. 단순한 기하학적 변형은 시간-주파수 도메인의 복잡한 패턴을 충분히 반영하지 못하며, GAN 기반 생성 기법은 훈련의 불안정성과 해석 가능성 부족으로 인해 실제 적용에 어려움이 따른다[10]. 특히, 생성된 데이터가 차량 소음처럼 고차원적이고 비선형적인 특성을 충분히 반영하지 못하는 경우가 많아, 기존 증강 방법은 이러한 변칙적 상황에서 성능 저하를 겪는다. 이러한 한계를 극복하기 위해 본 논문은 확산 모델 기반의 고성능 신호 증강 기법을 제안한다. 확산 모델은 초기 잡음 상태에서 점진적으로 신호를 복원함으로써, 차량 소음의 미세하고 복합적인 패턴을 정밀하게 학습할 수 있다[10]. 최근 연구들에서도 확산 모델이 음성 합성, 음향 향상, 이상 음향 탐지 등 다양한 분야에서 기존 생성 모델을 능가하는 성능을 보이며, 안정적으로 복잡한 시간-주파수 구조를 학습할 수 있음을 입증하고 있다[11-13]. 본 연구는 이러한 확산 모델의 특성을 차량 내 소음 분류를 위한 데이터 증강에 적용하고, 여기에 전문가 지식 기반의 군집화 기법을 결합하여 증강 데이터에 대한 라벨링 정확성과 효율성을 동시에 확보하는 새로운 접근을 제안한다. 이를 통해 시간과 자원의 소모를 줄이면서도 높은 품질의 증강 데이터를 확보할 수 있으며,ㅊ복잡한 실환경에서도 효과적으로 작동하는 데이터 증강 전략을 제시한다. 3. 제안하는 방법본 연구에서는 총 10개 클래스로 구성된 차량 내 소음 데이터를 30채널 센서 배열을 통해 수집하고, 44.1kHz로 샘플링하였다. 수집된 오디오 신호는 STFT(Hanning 윈도우, 1024-point, hop size 256)를 이용해 시간-주파수 도메인의 스펙트로그램으로 변환되며, 1초 길이의 고정된 윈도우로 분할하여 정규화 후 모델에 입력된다. 확산 모델은 DDPM 구조를 기반으로 하며, 1000 step의 노이즈 스케줄을 따라 학습된다. 학습된 모델은 denoising 및 pseudo-labeling 과정을 통해 새로운 합성 샘플을 생성한다. 이후 SSIM 기반 필터링과 KMeans 기반 군집화를 통해 전문가 지식에 따라 라벨을 할당하고, 기존 데이터와 함께 CNN 분류기의 학습에 사용된다. 이러한 처리 과정은 복잡한 차량 내 소음을 효과적으로 반영하며, 라벨링 비용을 줄이고 증강 데이터의 품질을 향상시키는 데 기여한다. 3.1. 단시간 푸리에 변환과 슬라이딩 윈도우 알고리즘단시간 푸리에 변환(STFT)은 시간-주파수 분석을 위해 신호에 대해 슬라이드 하면서 부분적으로 주파수 성분을 추출하는 방법이다. 주파수 분석은 시간 도메인 신호를 주파수 도메인으로 변환하여, 특정 시간대에서 주파수 성분을 분석할 수 있게 해준다. 이를 통해 차량 내 소음의 특징을 더 정밀하게 추출할 수 있다. 특히 차량 소음 분석에서는, 다양한 시간대에 발생하는 주파수 변화를 탐지하여 각 소음의 특징을 정밀하게 분석하는데 사용된다. STFT는 일정한 윈도우 함수 [TeX:] $$V[n-p]$$로 신호를 분할하고, 각 윈도우에서 신호 [TeX:] $$y[p]$$의 주파수 성분을 분석한다. 수식 (1)에서 제시한 STFT는 복소수 주파수 성분을 계산하는 방법으로, 이는 차량 내부의 다양한 소음 패턴을 시간-주파수 영역에서 효율적으로 분석할 수 있도록 한다.
슬라이딩 윈도우 알고리즘은 연속적인 데이터에서 중첩된 윈도우를 사용하여 데이터의 통계를 연산한다. 각 윈도우 내에서 주파수 특성을 분석한 후, 윈도우를 이동시키며 전체 신호를 분석한다. 수식 (2)에서는 윈도우 내에서 함수 [TeX:] $$f(k)$$를 적용하여 [TeX:] $$i$$번째 윈도우의 결과를 계산한다.
3.2 확산 모델 기반 신호 증강확산 모델 기반 신호 증강은 초기 잡음 상태에서 목표 데이터 분포에 도달하는 확률적 과정을 역으로 추적하며, 시간에 따라 점진적으로 노이즈가 첨가된 데이터로부터 원 데이터를 복구한다. 이는 마르코프 체인(Markov chain)에 기반하여 점진적으로 노이즈가 추가된 상태에서 데이터를 생성하고, 그 과정을 역으로 추적하여 원래의 신호를 복구하는 것이다. 이 과정에서 가우시안 노이즈가 데이터에 추가되며, 노이즈가 첨가된 데이터를 생성하고, 해당 데이터를 기반으로 한 스텝 이전 상태를 복구한다. 이 방법은 다양한 소음 데이터의 복잡한 패턴을 다루는 데 적합하며, 차량 내부에서 발생하는 다양한 주파수의 소음을 복원하는 데 사용된다. 수식 (3)에서 [TeX:] $$\epsilon$$은 가우시안 노이즈이고, 원본 데이터에서 노이즈를 점차적으로 추가하여 [TeX:] $$u_t$$를 생성한다. 수식 (4)에서 시간 [TeX:] $$t$$에서 노이즈가 첨가된 [TeX:] $$u_t$$에서 한 스텝 이전의 [TeX:] $$u_{t-1}$$을 추정한다. 여기서 [TeX:] $$\gamma_t$$는 노이즈 스케줄, [TeX:] $$\omega\left(u_t, t\right)$$는 학습된 노이즈 모델을 통해 얻어진 노이즈 예측이다.
(4)[TeX:] $$u_{t-1}=\frac{1}{\sqrt{1-\gamma_t}}\left(u_t-\frac{\gamma_t}{\sqrt{1-\sum_{s=1}^t \gamma_s}} \omega_t\left(u_t, t\right)\right)$$3.3 이미지 유사성 비교 및 전문가 지식 기반의 클러스터링전문가 지식 기반의 클러스터링 기법은 군집화(Clustering) 작업을 통해 확산 모델이 생성한 데이터를 가까운 군집 중심에 할당하고, 해당 군집에 전문가가 정의한 라벨을 적용하는 과정이다. 이는 랜덤하게 생성된 이미지를 일일이 라벨링하지 않으면서도 전문가의 지식을 활용할 수 있다. 특히 차량 소음 분류 작업에서는 복잡하고 불규칙적인 상황에서 소음을 분류하기위해 고도의 확산모델을 바탕으로 대량의 데이터셋을 생성하기 때문에 전문가가 수동으로 라벨링하기 어려운 상황이다. 따라서 논문은 군집화 과정을 통해 비슷한 특성을 가진 데이터 그룹끼리 묶고, 해당 군집에 전문가가 정의한 라벨을 할당한다. 수식 (5)에서 [TeX:] $$P L\left(x_i\right)$$는 각 데이터 [TeX:] $$X_i$$가 속하는 군집 [TeX:] $$c_j$$의 레이블 [TeX:] $$l\left(c_j\right)$$와 일치하며, 이는 데이터가 [TeX:] $$K$$에 정의된 군집들 중 하나이다. [TeX:] $$X_i$$는 유클리디언 거리의 제곱 [TeX:] $$\left\|x_i-\mu_c\right\|^2$$으로 측정된 가장 가까운 군집 중심 [TeX:] $$\mu_c$$를 찾아 군집화 분석한다. 구조화된 집합을 형성하여 데이터 간의 상대적 위치와 전체의 구조를 파악하고, 전문가 지식을 기반으로 군집의 라벨을 할당하여 데이터를 증강한다.
(5)[TeX:] $$\begin{aligned} P L\left(x_i\right)=l\left(c_j\right) \mid x_i & \in C_j, C_j \\ & =\underset{c \in K}{\arg \min }\left\|x_i-\mu_c\right\|^2 \end{aligned}$$이 과정에서 생성된 이미지들간 유사성을 비교하기 위해 구조적 유사도 (Structural similarity index) 척도가 활용되며, 이는 이미지의 구조적 변화를 감지하는 방식으로 설계된 지표이다. 두 이미지 간의 구조, 밝기, 대비의 유사성을 측정한다. 수식 (6)에서는 a, b는 비교할 두 이미지이고, 각각 원본 이미지와 모델 별 생성 이미지를 나타낸다. [TeX:] $$m_a$$와 [TeX:] $$m_b$$는 각각 두 이미지의 평균값, [TeX:] $$s_a^2$$와 [TeX:] $$s_b^2$$는 각각 두 이미지의 공분산이며 두 이미지의 유사성을 모델 별로 비교한다.
4. 실험 결과4.1 차량 내 소음 데이터셋 수집표 2는 차량 내부에서 수집된 소음 데이터를 제시한다. 30개 센서의 배열로 얻어 샘플을 STFT 스펙트로그램으로 변환하였다. 차원은 각각 윈도우의 총 수, 윈도우의 크기, 주파수 대역 별 강도, 그리고 센서의 수이다. 표(Table) 2. 통제된 환경에서 샘플링된 차량 소음별 유형 및 길이(Types and Duration of Vehicle Noises Sampled in a Controlled Environment)
4.2 차량 내 소음 데이터 생성 및 분류 성능 비교표 3에서는 전통적인 데이터 증강 기법과 최신 딥러닝 기반 증강 방법의 분류 성능을 다양한 노이즈 레벨에서 비교하였다. 제안된 DDPM-augmented CNN 방식은 모든 노이즈 조건에서 가장 높은 정확도를 기록하였으며, 전통적인 증강 방식 대비 최대 1.06%p, GAN 기반 증강 방식 대비 최대 0.06%p의 성능 향상을 달성하였다. 표(Table) 3. 기존 생성 방식과 DDPM 기반 생성 비교(Comparison Between Traditional Generation Methods and DDPM-Based Generation)
표 4에서는 다양한 머신러닝 및 딥러닝 모델의 성능을 비교한 결과, 제안한 방법은 모든 노이즈 레벨에서 가장 높은 성능을 보였으며, CNN 기반 모델의 높은 성능 대비 최대 0.45%p의 향상이 있었다. 이를 통해 확산 모델 기반 증강 기법이 CNN의 성능을 극대화함을 알 수 있다. 표(Table) 4. 모델 별 분류 정확도 성능 비교(Performance Comparison of Classification Accuracy by Model)
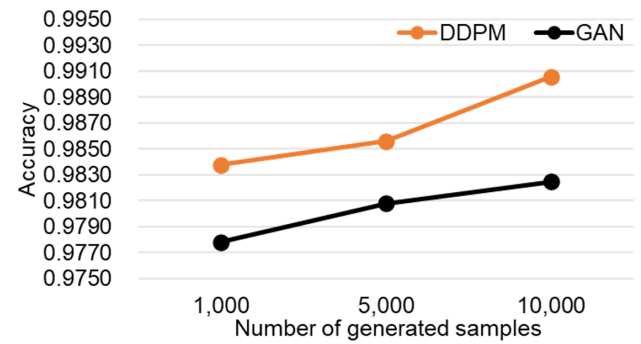
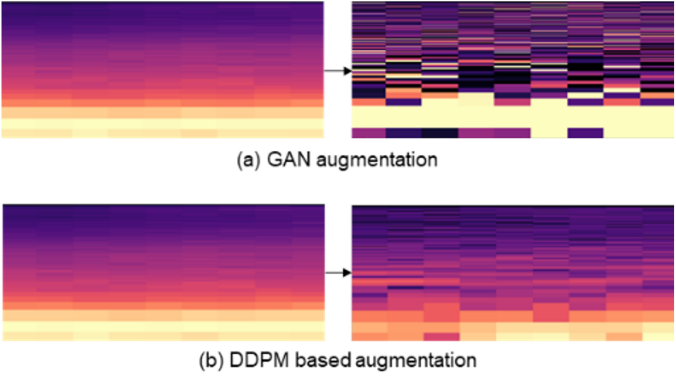
그림 2에서는 데이터 생성 방법에 따른 생성된 샘플 수 변화에 따른 정확도를 비교하였다. 제안한 방법은 생성된 샘플 수가 증가할수록 정확도가 지속적으로 향상되는 경향을 보였으며, GAN을 사용한 모델과 비교할 때 최대 0.81%p의 성능 개선을 보였다. 이를 통해 제안된 방식이 GAN보다 더 효율적으로 학습 데이터를 증강할 수 있음을 확인할 수 있다. 그림 3의 SSIM 평가 결과, 제안한 확산 모델은 GAN보다 더 세부적인 특징을 잘 포착하여 더 높은 품질의 샘플을 생성하였다. 이는 본 방식이 데이터 증강에서 더 높은 품질과 성능을 제공함을 입증한다. 4.2 전문가 지식 기반의 클러스터링 적용 전후 성능 비교그림 4에서는 논문에서 제안한 전문가 지식 기반의 군집화 과정을 적용한 전후의 증강 데이터 공간을 시각적으로 비교하였다. (a)에서는 군집화 과정이 적용되지 않은 데이터를, (b)에서는 군집화가 적용된 데이터 공간의 모습을 보여준다. 전문가 지식 기반의 군집화가 적용되지 않은 경우, 데이터의 그룹이 불명확하고 불규칙하게 분포되어 있는 반면, 군집화를 적용한 경우에는 데이터가 명확하게 구분된 군집으로 시각화된다. 그림(Fig.) 4. 전문가 지식 기반 클러스터링으로 라벨링된 증강 데이터 공간 시각화(Visualization of an Augmented Data Space Labeled by Expert Knowledge-guided Clustering) 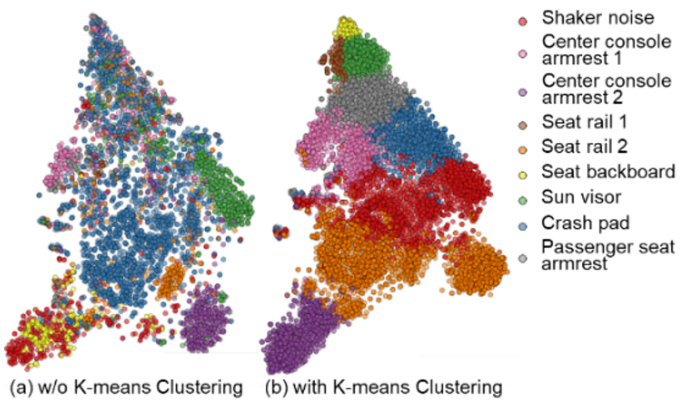 이 실험은 전문가 지식 기반의 군집화를 적용함으로써 데이터 증강 과정 중 라벨링 과정의 효율성을 극대화할 수 있음을 시각적으로 증명한다. 군집화된 각 그룹은 전문가의 사전 정의된 라벨에 의해 정밀하게 분류될 수 있으며, 이를 통해 일일이 데이터를 라벨링하지 않으면서도 전문가의 지식을 활용할 수 있는 방법을 제시하였다. 특히, 소음 데이터와 같이 불규칙한 데이터 분포를 가진 환경에서 군집화된 데이터를 기반으로 효율적인 분류 성능 향상을 기대할 수 있다. 이 실험은 데이터 라벨링에 소요되는 비용과 시간을 절감하면서도 성능을 향상시킬 수 있는 효과적인 방법임을 입증한다. 5. 결론 및 향후 연구본 연구에서는 차량 내 소음 분류 성능을 향상시키기 위해 확산 모델 기반 신호 증강 방법과 전문가 지식 기반의 군집화 기법을 결합한 새로운 소음 분류 방법을 제안하였다. 확산 모델을 통해 다양한 소음 조건을 반영한 합성 데이터를 생성하고, 전문가 지식 기반의 군집화를 통해 증강된 데이터에 자동으로 라벨을 부여함으로써, 기존의 딥러닝 기반 분류 방법들과 비교해 현저한 성능 개선을 이루었다. 본 연구에서는 차량 내 소음 분류 성능을 향상시키기 위해 확산 모델 기반 신호 증강 방법과 전문가 지식 기반의 군집화 기법을 결합한 새로운 소음 분류 방법을 제안하였다. 확산 모델을 통해 다양한 소음 조건을 반영한 합성 데이터를 생성하고, 전문가 지식 기반의 군집화를 통해 증강된 데이터에 자동으로 라벨을 부여함으로써, 기존의 딥러닝 기반 분류 방법들과 비교해 현저한 성능 개선을 이루었다. 본 연구의 결과는 차량 내 소음 분류 분야에서 신호 증강과 전문가 지식 기반의 군집화 기법을 결합한 새로운 접근법이 기존 방법에 비해 더 높은 성능을 제공함을 입증하였으며, 이를 통해 실시간 소음 모니터링 및 결함 진단 시스템에 적용할 수 있는 가능성을 보여준다. 향후 연구에서는 클래스 조건 정보를 포함한 조건부 확산 모델(Conditional Diffusion Model)을 도입하여, 특정 소음 유형을 제어 가능한 방식으로 생성함으로써 클래스 간 구분 성능을 강화하고자 한다. 또한, 능동 학습 기반의 반자동 라벨링 기법과 도메인 적응 성능 평가 지표(BWT, forgetting 등)를 추가적으로 도입함으로써, 복잡하고 변동성 높은 환경에서도 일반화 가능한 차량 소음 분류 시스템으로 확장할 수 있을 것이다. References
|
StatisticsCite this articleIEEE StyleS. Choi, M. Baek, S. Buu, "Diffusion Model-based In-vehicle Noise Augmentation through Expert Knowledge-guided Clustering," Journal of KIISE, JOK, vol. 52, no. 9, pp. 771-777, 2025. DOI: 10.5626/JOK.2025.52.9.771.
ACM Style Seok-Hun Choi, Mugeun Baek, and Seok-Jun Buu. 2025. Diffusion Model-based In-vehicle Noise Augmentation through Expert Knowledge-guided Clustering. Journal of KIISE, JOK, 52, 9, (2025), 771-777. DOI: 10.5626/JOK.2025.52.9.771.
KICS Style Seok-Hun Choi, Mugeun Baek, Seok-Jun Buu, "Diffusion Model-based In-vehicle Noise Augmentation through Expert Knowledge-guided Clustering," Journal of KIISE, JOK, vol. 52, no. 9, pp. 771-777, 9. 2025. (https://doi.org/10.5626/JOK.2025.52.9.771)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||